Coni
Client
12%
AI TRANSFORMATION
Coni
Client
Construction
Industry
AI Structured Extraction
Services
Romania
Region
2026
Year
Romanian businesses drown in documents: invoices, contracts, official letters, authorisations, memos. Most arrives as PDFs, scans, or Word files, filed under a filename that made sense to whoever uploaded it that day. A year in, the archive is unsearchable. You can find a file only if you remember its name. You cannot ask the archive to show every invoice from Q3 over fifty thousand euros, because none of that lives in a queryable field.
The bottleneck is not storage, it is metadata. Extracting structured fields by hand from hundreds of documents a week is work nobody has time to do.
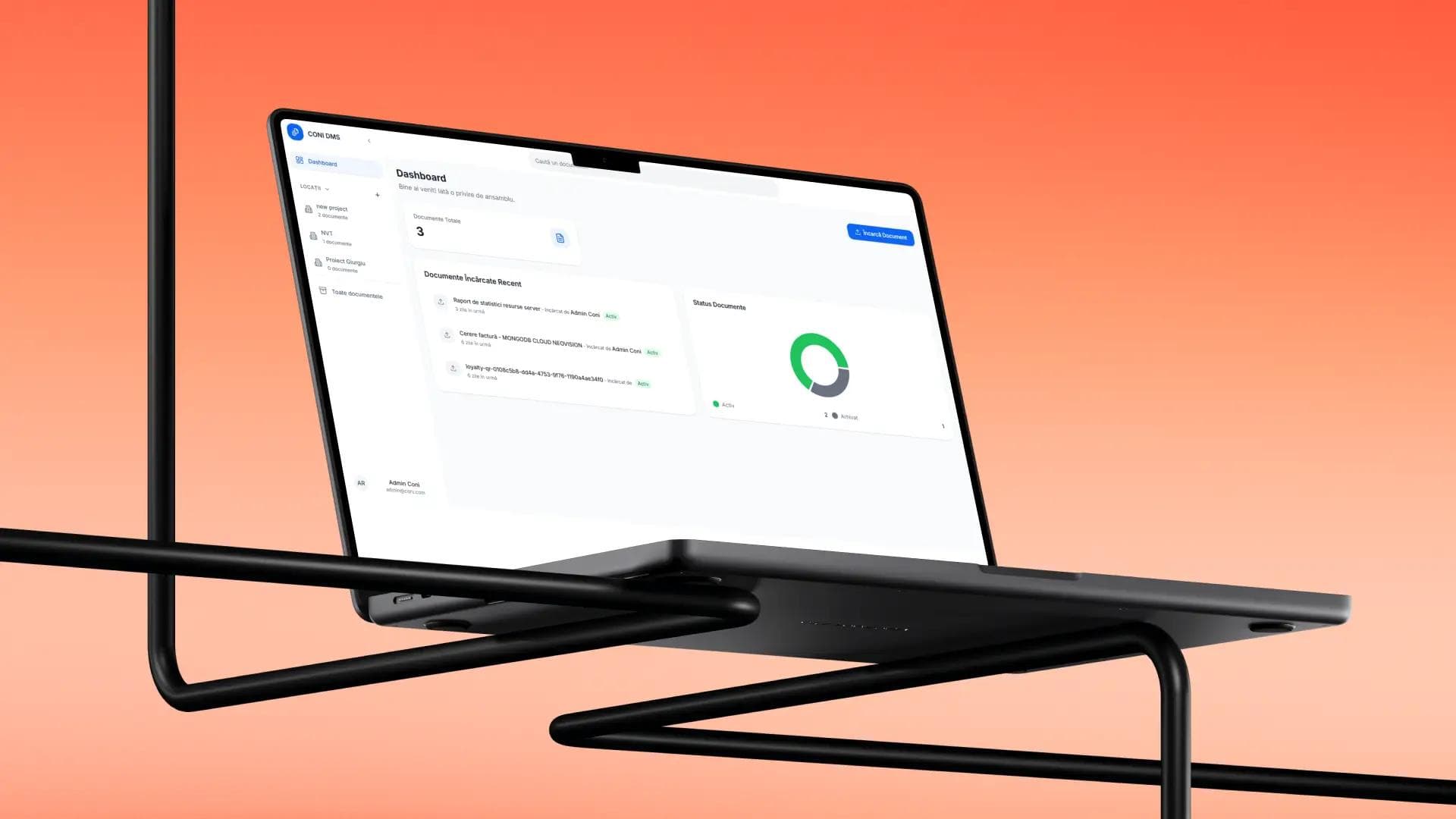
A four-stage pipeline runs the moment a file hits the upload endpoint: extract the text, ask a model for structured metadata, write to a searchable store, surface it for review. Upload returns in under a second; the heavy work runs on a queue worker while the user keeps working. Every supported file type has its own extraction path, each guarded so a missing library degrades gracefully: digital PDFs read directly, Word walks the document tree preserving tables, Excel keeps column alignment, and scanned images go through Tesseract OCR in Romanian and English at once. Extracted text goes to a Chat Completions call with a locked 12-field schema, returning the same fields in the same shape every time, with temperature low so re-uploads produce identical metadata.
<1 min
Upload to searchable record
4
Input formats, one output shape
12 fields
Locked metadata schema
A user drops a PDF, walks to the coffee machine, comes back to a filled-out metadata card ready to save. The archive speaks the user's language, with diacritics preserved, and every document records the tokens it consumed.
AI TRANSFORMATION
Coni
Client
Construction
Industry
AI Structured Extraction
Services
Romania
Region
2026
Year
Romanian businesses drown in documents: invoices, contracts, official letters, authorisations, memos. Most arrives as PDFs, scans, or Word files, filed under a filename that made sense to whoever uploaded it that day. A year in, the archive is unsearchable. You can find a file only if you remember its name. You cannot ask the archive to show every invoice from Q3 over fifty thousand euros, because none of that lives in a queryable field.
The bottleneck is not storage, it is metadata. Extracting structured fields by hand from hundreds of documents a week is work nobody has time to do.
A four-stage pipeline runs the moment a file hits the upload endpoint: extract the text, ask a model for structured metadata, write to a searchable store, surface it for review. Upload returns in under a second; the heavy work runs on a queue worker while the user keeps working. Every supported file type has its own extraction path, each guarded so a missing library degrades gracefully: digital PDFs read directly, Word walks the document tree preserving tables, Excel keeps column alignment, and scanned images go through Tesseract OCR in Romanian and English at once. Extracted text goes to a Chat Completions call with a locked 12-field schema, returning the same fields in the same shape every time, with temperature low so re-uploads produce identical metadata.
<1 min
Upload to searchable record
4
Input formats, one output shape
12 fields
Locked metadata schema
A user drops a PDF, walks to the coffee machine, comes back to a filled-out metadata card ready to save. The archive speaks the user's language, with diacritics preserved, and every document records the tokens it consumed.
